The Scientist and Engineer's Guide to
Digital Signal Processing
By Steven W. Smith, Ph.D.
Book Search

Table of contents
- 1: The Breadth and Depth of DSP
- 2: Statistics, Probability and Noise
- 3: ADC and DAC
- 4: DSP Software
- 5: Linear Systems
- 6: Convolution
- 7: Properties of Convolution
- 8: The Discrete Fourier Transform
- 9: Applications of the DFT
- 10: Fourier Transform Properties
- 11: Fourier Transform Pairs
- 12: The Fast Fourier Transform
- 13: Continuous Signal Processing
- 14: Introduction to Digital Filters
- 15: Moving Average Filters
- 16: Windowed-Sinc Filters
- 17: Custom Filters
- 18: FFT Convolution
- 19: Recursive Filters
- 20: Chebyshev Filters
- 21: Filter Comparison
- 22: Audio Processing
- 23: Image Formation & Display
- 24: Linear Image Processing
- 25: Special Imaging Techniques
- 26: Neural Networks (and more!)
- 27: Data Compression
- 28: Digital Signal Processors
- 29: Getting Started with DSPs
- 30: Complex Numbers
- 31: The Complex Fourier Transform
- 32: The Laplace Transform
- 33: The z-Transform
- 34: Explaining Benford's Law
How to order your own hardcover copy
Wouldn't you rather have a bound book instead of 640 loose pages?Your laser printer will thank you!
Order from Amazon.com.
Chapter 2: Statistics, Probability and Noise
Statistics is the science of interpreting numerical data, such as acquired signals. In comparison, probability is used in DSP to understand the processes that generate signals. Although they are closely related, the distinction between the acquired signal and the underlying process is key to many DSP techniques.
For example, imagine creating a 1000 point signal by flipping a coin 1000 times. If the coin flip is heads, the corresponding sample is made a value of one. On tails, the sample is set to zero. The process that created this signal has a mean of exactly 0.5, determined by the relative probability of each possible outcome: 50% heads, 50% tails. However, it is unlikely that the actual 1000 point signal will have a mean of exactly 0.5. Random chance will make the number of ones and zeros slightly different each time the signal is generated. The probabilities of the underlying process are constant, but the statistics of the acquired signal change each time the experiment is repeated. This random irregularity found in actual data is called by such names as: statistical variation, statistical fluctuation, and statistical noise.
This presents a bit of a dilemma. When you see the terms: mean and standard deviation, how do you know if the author is referring to the statistics of an actual signal, or the probabilities of the underlying process that created the signal? Unfortunately, the only way you can tell is by the context. This is not so for all terms used in statistics and probability. For example, the histogram and probability mass function (discussed in the next section) are matching concepts that are given separate names.
Now, back to Eq. 2-2, calculation of the standard deviation. As previously mentioned, this equation divides by N-1 in calculating the average of the squared deviations, rather than simply by N. To understand why this is so, imagine that you want to find the mean and standard deviation of some process that generates signals. Toward this end, you acquire a signal of N samples from the process, and calculate the mean of the signal via Eq. 2.1. You can then use this as an estimate of the mean of the underlying process; however, you know there will be an error due to statistical noise. In particular, for random signals, the typical error between the mean of the N points, and the mean of the underlying process, is given by:
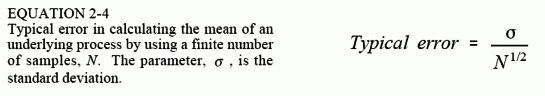
If N is small, the statistical noise in the calculated mean will be very large. In other words, you do not have access to enough data to properly characterize the process. The larger the value of N, the smaller the expected error will become. A milestone in probability theory, the Strong Law of Large Numbers, guarantees that the error becomes zero as N approaches infinity.
In the next step, we would like to calculate the standard deviation of the acquired signal, and use it as an estimate of the standard deviation of the underlying process. Herein lies the problem. Before you can calculate the standard deviation using Eq. 2-2, you need to already know the mean, μ. However, you don't know the mean of the underlying process, only the mean of the N point signal, which contains an error due to statistical noise. This error tends to reduce the calculated value of the standard deviation. To compensate for this, N is replaced by N-1. If N is large, the difference doesn't matter. If N is small, this replacement provides a more accurate
estimate of the standard deviation of the underlying process. In other words, Eq. 2-2 is an estimate of the standard deviation of the underlying process. If we divided by N in the equation, it would provide the standard deviation of the acquired signal.
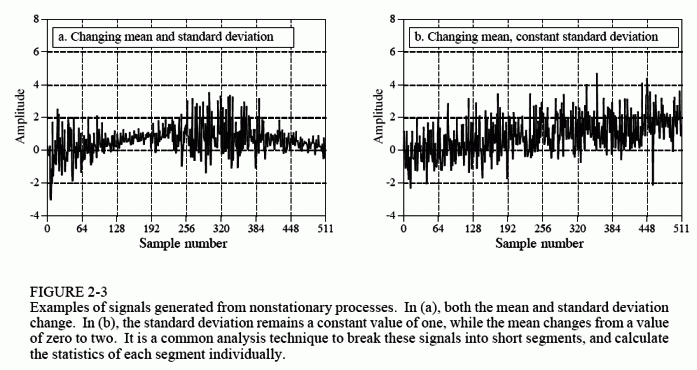
As an illustration of these ideas, look at the signals in Fig. 2-3, and ask: are the variations in these signals a result of statistical noise, or is the underlying process changing? It probably isn't hard to convince yourself that these changes are too large for random chance, and must be related to the underlying process. Processes that change their characteristics in this manner are called nonstationary. In comparison, the signals previously presented in Fig. 2-1 were generated from a stationary process, and the variations result completely from statistical noise. Figure 2-3b illustrates a common problem with nonstationary signals: the slowly changing mean interferes with the calculation of the standard deviation. In this example, the standard deviation of the signal, over a short interval, is one. However, the standard deviation of the entire signal is 1.16. This error can be nearly eliminated by breaking the signal into short sections, and calculating the statistics for each section individually. If needed, the standard deviations for each of the sections can be averaged to produce a single value.